by Aislynn Li
2022 May
Please enjoy 月光舞厅 by 跳大海 while reading this documentation:
Come Dance With Model is an interactive dancing web where users can dance with a DCGAN dancing model. The positions of different parts of the user’s body are calculated and mapped to “positions” in the latent space of the generated images. Therefore, when users dance in front of the screen, they create a walk through the latent space of postures, which visually makes the dance of the model. Not only that, users can wave their two hands in front of the screen to reach the four buttons next to the screen to choose the mode of the ballroom. Among them, the circle’s position in the background in the default mode is calculated in the same way, but using the position of the model’s images as the original data, while generating a representation of the positions of the user’s body.

Inspiration
I really like the term “latent space walk”. It is essentially a continuous display of images generated by a GANs model. Describing the database of images as latent space, the ID code of images as “position”, and the process of the display as taking a walk in the latent space obsessed me. After different choices of positions, the walk itself can have meaning. For example, if the original samples are flowers, the walk can show the process of a flower blossoming.
So I got an idea: can we map the positions of our body parts with the positions in the latent space. Then when we move our bodies, we will have the walk correspondingly. After some discussion with professor Gottfried, the idea of using postures was raised. In this case, the walk can be transformed into a visual dance of the model. In other words, the user dances in front of the screen and the model dances on the screen correspondingly.
Process
- Model Training
I used 868 dancing images of 64×64 pixels from google and dance videos to train the DCGAN model using Colab. These images are basically clean and neat white or gray backgrounds, with obvious character movements. I chose the picture of multiple people instead of one person because the difference in amplitude of movements and the difference in positions is greater, which will make it more obvious when the model is dancing.

I also trained a model from a set of pictures of dance movements I took a long time ago. The original material had about 300 images, and I tried to train it twice, once with just those 300 images, and once by duplicating them twice and training with 900 images. But neither result was very satisfactory.
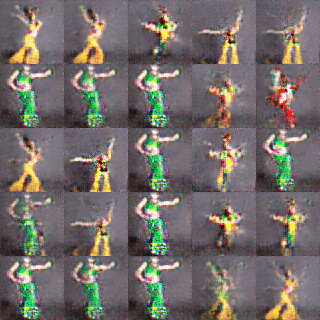
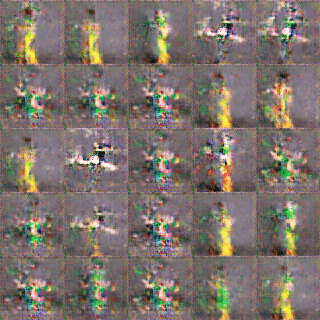
(15300 times vs 15600 times)
I do not know what the specific reason is, but the effect of training is very repeated. It is easy to have a good effect, and then after a few times training, the effect suddenly becomes very poor. This leads to very blurred and unrecognizable movements of the trained model. Therefore, I chose the first model.
- Mapping
At the very beginning, my idea was that the dance movements were constantly changing from one picture to the next. Then I could keep generating random coordinates of the next picture and “reach” the next picture through my movements.
My first experiment was to control whether to reach the next picture by the position of the body, that is, the nose switches to the next picture by reaching the left and right sides. The problem with this experiment was how to use multiple body parts and also how to go from the left and right extremes to a more generalized destination.
Therefore, my second experiment was to use the speed of body parts to switch to the next image. When the speed reaches a certain level, the image will switch to the next one. But in practice, the effect is not quite like dancing. So this experiment was discarded.
As suggested by professor Gottfried, I thought it would be better to directly map the positions of body key points to the positions. In this case, the transitions would be smoother, while it could still make a big movement difference.
At first, I directly map the body data and put the dcgan.generate() directly into the loop, so it caused a lot of lag.

With the help of Gottfried, I only let the converted body data influence part of the position, while the other parts stay the same. And I also get the dcgan.generate() out of the loop by simply storing the data in vector[].
To make the mapping richer and various, I added random_vector[] that will generate different positions each time the user opens the page. Therefore, each time the mapping start points are different. I also used different the change_num to determine different map ways.


- Modes
To make it more interesting and to enhance the dance floor vibe, I added four modes/patterns.
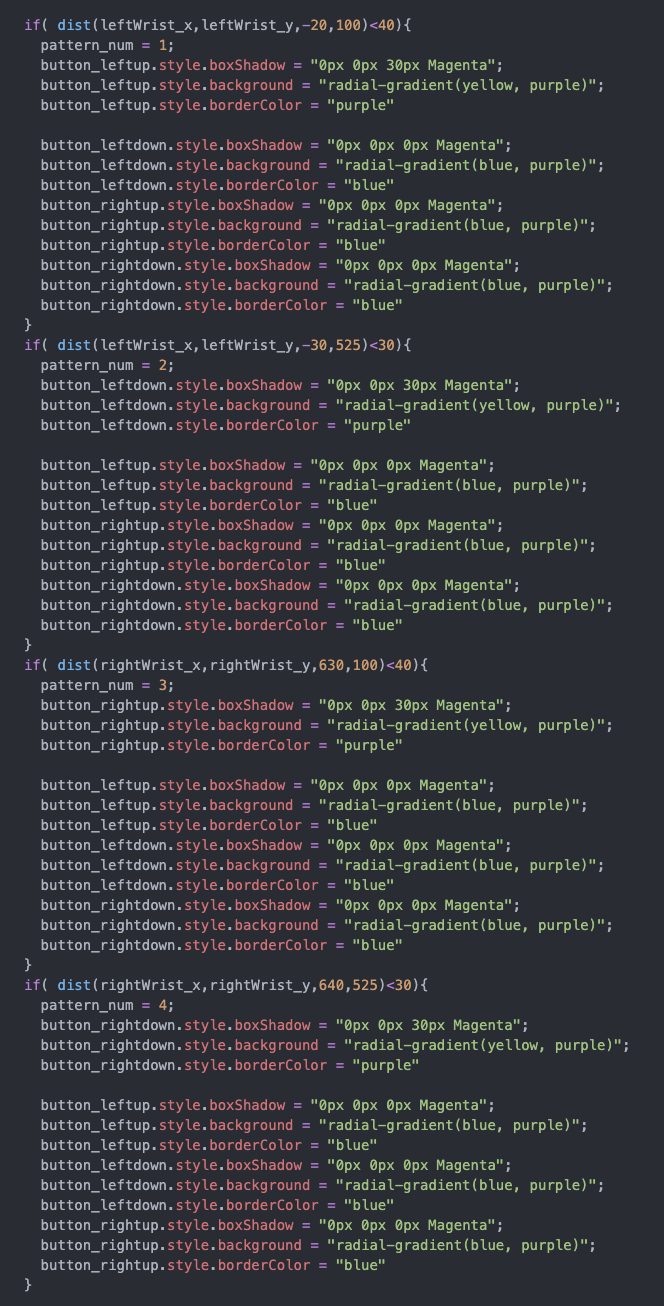
The first one uses the position of two wrists to control the movement of the elements in the background, while the background colors of the generated images also change.

Here’s the code:


The second one simply uses the tint() and a repeated appearance of a black background to create a slow-motion, with delays and ghosting.

The third mode creates the circles in the background, building the vibe of the lights in a dance hall. Previously, I used the body position data as the raw data, and after mapping, it corresponds to the position of the model in the latent space. In this mode, the data of the model in the latent space becomes the source data, and the same map method is used to generate the two-dimensional positions, which is the position of the generated circles. It can be said that the trajectory of these circles is a representation of our body positions in the model’s view.


The fourth mode is 5 shining spotlights, with different colors, lengths, positions, and speeds:


Finally, to make it more consistent, since the rest of the commands are made by the positions of body parts, I used the positions of the wrists to select modes.
To conclude, here’s the code: https://github.com/AislynnLi/machine-learning/tree/main/ml%20final
Reflection
Overall I am pretty satisfied with the final result. To my surprise, the reaction time between the body’s movements and the model’s movements is not too long. The model’s dance can be said to be relatively smooth. And the model generates images whose movements are easily recognizable even in 64×64 pixels, which also requires great luck.
I also like the fact that there are four modes, and that each mode is again not just different in appearance, but also in terms of control mode and reaction mode, which makes it very interesting to me.
During the presentation, I received two pieces of feedback that were rather unexpected for me. One was from Hubert Lu, that was, he didn’t understand that the picture in the middle was already the picture generated by my model, but thought it was a guide. I think on one hand my website needs more prerequisite introduction, and on the other hand, because the posture in the model-generated image is different from the user’s posture, so he didn’t know there is a correspondence between the two at first. I might also be able to use PoseNet to recognize and check the generated image until the image makes the user’s movement. This is a developing direction of this project.
The second feedback was from professor Moon that the two buttons underneath made him think he should use his feet to control, not his hands. I think apart from the factor of insufficient guidance, it may also be because its recognition is not that sensitive, resulting in the hand to that position did not make the model respond quickly, so the user mistakenly thought it was with the foot. I think I can continue to adjust the parameters until it can be more sensitive to identify the location. I can also add the hand pattern to the icon to guide the user.
Professor Gottfried gave feedback on the interface design. I’ve changed the title from”Are You Ready To Dance” since it has not that much relationship with my concept, to “Come Dance With Model”. But I don’t have a better idea yet for the rest of the page, such as the outfit or even the positions of the four buttons. The way I have it now is actually inspired by the dancing machine, but it makes the whole page look more retro and contradicts my futuristic concept again. I will continue to think about it.
Professor Moon also suggested I have a look at William Forsythe‘s work to try to instruct users more about the posture, which is quite in line with my first experiment: if the user achieves a certain posture, the model will change to the next picture. That experiment can be my start point. He also suggested I use other GANs models to see how the results change, and even make it into 3D. I agree there is a lot of room for improvement in both the models and samples.
Finally, thanks to professor Gottfried for inspiration, mental and technical support! Thanks to professor Moon, Hubert Lu, Cindy Li, Jane Wu, and Julie Tian for giving feedback on my project and the song!