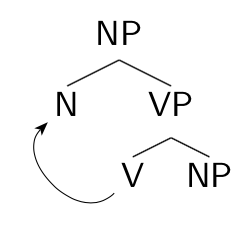
 A popular account of what Grimshaw called “complex event nominalizations” (cf. John’s frequent destruction of my ego) involves postulating that these nominalizations involve a nominalizing head taking a VP complement. When the head V of the VP moves to merge with the nominalizing head, the resulting structure has the internal syntactic structure of an NP, not a VP. For example, there’s no accusative case assignment to a direct object, and certain VP-only complements like double object constructions (give John a book) and small clauses (consider John intelligent) are prohibited (*the gift of John of a book, *the consideration of John intelligent).
A popular account of what Grimshaw called “complex event nominalizations” (cf. John’s frequent destruction of my ego) involves postulating that these nominalizations involve a nominalizing head taking a VP complement. When the head V of the VP moves to merge with the nominalizing head, the resulting structure has the internal syntactic structure of an NP, not a VP. For example, there’s no accusative case assignment to a direct object, and certain VP-only complements like double object constructions (give John a book) and small clauses (consider John intelligent) are prohibited (*the gift of John of a book, *the consideration of John intelligent).
Note that this analysis relies on the assumption that head movement (of V to N) has an impact on syntax. Before head movement applies, the verb phrase has verb phrase syntax, with the possibility of accusative case, small clauses and double object complements. After head movement applies, there is no VP syntax and the internal structure of the NP is that of any NP.
Within the development of Distributed Morphology, these consequences of head movement fit within the general approach of Marantz (1981, 1984) in which the operation of “morphological merger” (later equated with head movement and adjunction) causes structure collapsing. That is, when the verb merges with the nominal head, the VP effectively disappears (in Baker’s 1985 version, the structure doesn’t disappear but rather becomes “transparent”).
In a recent book manuscript (read this book!), Jim Wood (2020) argues that the VP account is not appropriate for Icelandic complex event nominalizations, and probably not right for English either. Among the pieces of evidence that Wood brings to the argument, perhaps the most striking is the observation that verbs in these nominalizations do not assign the idiosyncratic “quirky” cases to their objects that they do in VPs. If the VP analysis of complex event nominalizations is indeed wrong, then one might conclude that morphological merger-driven clause collapsing is simply not part of syntactic theory. It’s worth asking, however, what the motivation was for these consequences of morphological merger (or, head movement and adjunction) in the first place, and where we stand today with respect to the initial motivation for these mechanisms.
Allow me a bit of autobiography and let’s take a trip down memory lane to the fall of 1976. That fall I’m a visiting student at MIT, and I sit in on David Perlmutter’s seminar on Relational Grammar (RG). I meet Alice Harris and Georgian, my notebook fills with stratal diagrams, and I’m introduced to the even then rather vast set of RG analyses of causative constructions and of advancements to 2 (which include the “applicative” constructions of Bantu). Mind blowing stuff. One aspect of RG that particularly stuck in my mind and that I would return to later was the role of morphology like causative and applicative affixes in the grammar. In RG, morphemes were reflective rather than causal; they “flagged” structures. So an affix on a verb was a signal of a certain syntactic structure rather than a morpheme that created or forced the structure.
In an important sense my dissertation involved the importing of major insights of RG into a more mainstream grammatical theory. (In linguist years, the fall of 1976 and the summer of 1981, when I filed my dissertation, are not that far apart.) Consider the RG analysis of causative constructions involving “causative clause union.” In this analysis, a bi-clausal structure, with “cause” as the head (the predicate, P) of the upper clause, becomes mono-clausal. Since the upper clause has a subject (a 1) and the lower clause has a subject (another 1), and there can be only one 1 per clause (the Stratal Uniqueness Law), something has to give when the clauses collapse. In the very general case, if the lower clause is intransitive, the lower subject becomes an object (a 2), now the highest available relation in the collapsed clause.
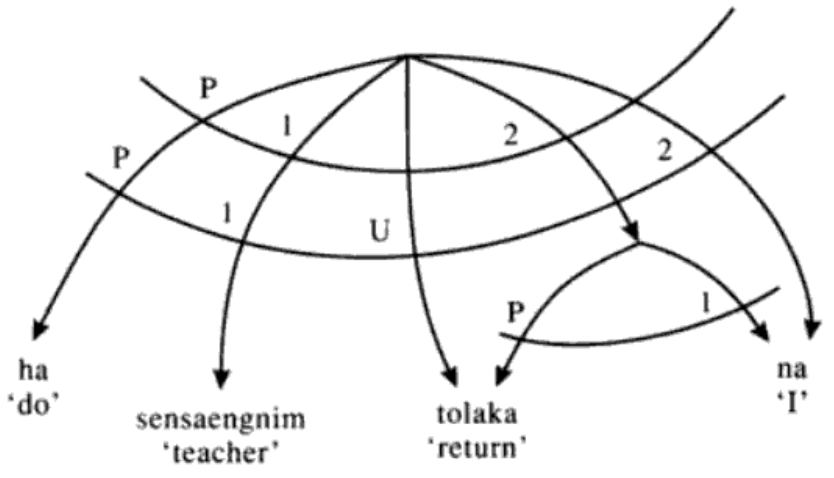
Stratal diagram for Korean causative of intransitive ‘Teacher made me return’ (Gerdts 1990: 206)
If the lower clause is transitive, its object (a 2) becomes the object of the collapsed clause, and the lower subject becomes an indirect object (a 3), the highest relation available.
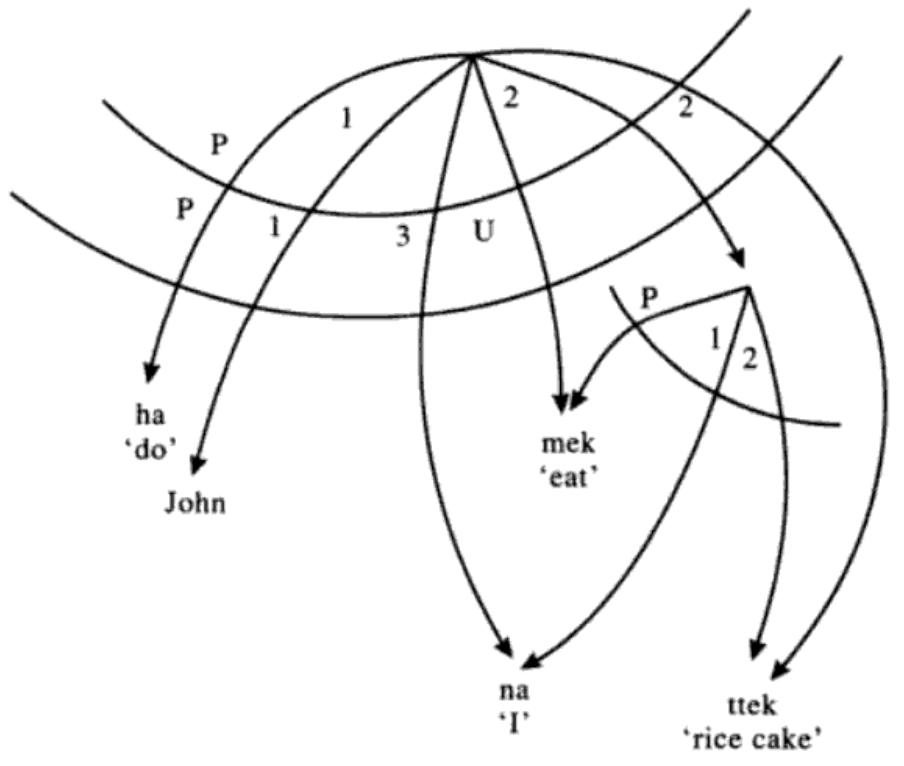
Stratal diagram for Korean causative of transitive ‘John made me eat the rice cake’ (Gerdts 1990: 206)
In languages with double object constructions like those of the Bantu family, after clause union with a lower transitive clause, the lower subject, now a 3, “advances” to 2, putting the lower object “en chômage” and creating a syntax that looks grammatically like that of John gave Mary a book in English, which also involves 3 to 2 advancement.
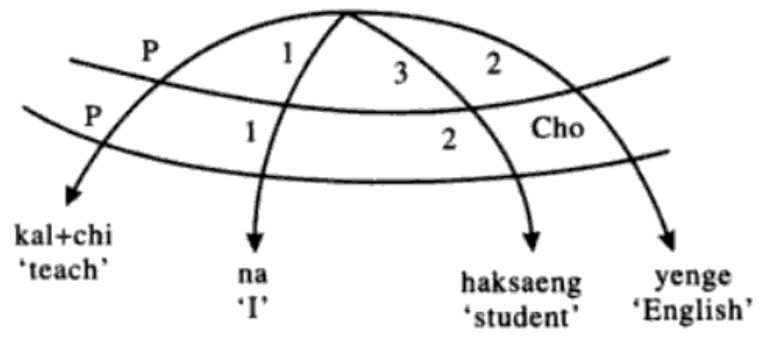
Stratal diagram for Korean ditransitive ‘I taught the students English’ (Gerdts 1990: 210)
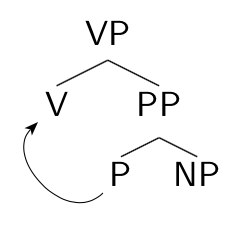 Within the Marantz (1981, 1984) framework, applicative constructions involve a PP complement to a verb, with the applicative morpheme as the head P of the PP. Morphological merger of the P head with the verb collapses the VP and PP together and puts the object of the P, the “applied object,” in a position to be the direct object of the derived applicative verb.
Within the Marantz (1981, 1984) framework, applicative constructions involve a PP complement to a verb, with the applicative morpheme as the head P of the PP. Morphological merger of the P head with the verb collapses the VP and PP together and puts the object of the P, the “applied object,” in a position to be the direct object of the derived applicative verb.
My general take in 1981 was that affixation (e.g., of a causative suffix to a verb) was itself responsible for the type of clause collapsing one sees in causative clause union. The lower verb, in a sentence that is the complement to the higher causative verb, would “merge” with the causative verb, with the automatic consequence of clause collapsing. I argued that a general calculus determined what grammatical roles the constituents of the lower clause would bear after collapsing, as in RG. There are many interesting details swirling around this analysis, and I proposed a particular account of the distinction between Turkish-type languages, in which the “causee” in a causative construction built on a transitive verb is oblique (dative, usually), and Bantu-type languages, in which this causee is a direct object in a double object construction. Read the book (particularly those of you habituated to citing it without reading – you know who you are).
At this point of time, nearly 40 years later, the analysis seems likely wrong-headed. Already by the late 1980’s, inspired by a deep dive into Alice Harris’s dissertation-turned-book on Georgian (1976, 1981), I had concluded that my 1981 analysis of causatives and applicatives was on the wrong track. Instead of bi-clausal (or bi-domain in the case of applicatives) structures collapsing as the result of morphological merger, a more explanatory account could be formulated if the causative and applicative heads were, in effect, heads on the extended projection of the lower verb. Affixation/merger of the verb with these causative and applicative heads would have no effect on the grammatical relations held by the different nominal arguments in these constructions. This general approach was developed by a number of linguists in subsequent decades, notably Pylkkänen (2002, 2008), Wood & Marantz (2017) and, for the latest and bestest, Nie (2020), which I’ll discuss in a later post.
The crucial point here is that the type of theory that underlies the N + VP analysis of complex event nominalizations has lost its raison d’être, thereby leaving the analysis orphaned. If morphological merger has no effect on the syntax, at least in terms of the collapsing of domains, then a nominalization formed by an N head and a VP complement could easily have the internal VP syntax of a VP under Tense. This does not describe complex event nominalizations, which are purely nominal in structure, but the discussion so far does not rule out a possible class of nominalizations that would show a VP syntax internally and NP syntax externally. As we discussed in an earlier post, English gerunds are not examples of such a construction, since they are not nominal in any respect (see Reuland 1983 and Kiparsky 2017). However, maybe such constructions do exist. If they don’t, it would important to understand if something in the general theory rules them out. We will return to this issue in a subsequent post.
References
Baker, M.C. (1985). Incorporation, a theory of grammatical function changing. MIT: PhD dissertation.
Gerdts, D.B. (1990). Revaluation and Inheritance in Korean Causative Union, in B. Joseph and P. Postal (eds.), Studies in Relational Grammar 3, 203-246. Chicago: University of Chicago Press.
Harris, A.C. (1976). Grammatical relations in Modern Georgian. Harvard: PhD dissertation.
Harris, A.C. (1981). Georgian syntax: A study in Relational Grammar. Cambridge: CUP.
Kiparsky, P. (2017). Nominal verbs and transitive nouns: Vindicating lexicalism. In C. Bowern, L. Horn & R. Zanuttini (eds.), On looking into words (and beyond), 311-346. Berlin: Language Science Press.
Marantz, A. (1981). On the nature of grammatical relations. MIT: PhD dissertation.
Marantz, A. (1984). On the nature of grammatical relations. Cambridge, MA: MIT Press.
Nie, Y. (2020). Licensing arguments. NYU: PhD dissertation. https://ling.auf.net/lingbuzz/005283
Pylkkänen, L. (2002). Introducing arguments. MIT: PhD dissertation.
Pylkkänen, L. (2008). Introducing arguments. Cambridge, MA: MIT Press.
Reuland, E.J. (1983). Governing –ing. Linguistic Inquiry 14(1): 101-136.
Wood, J., & Marantz, A. (2017). The interpretation of external arguments. In D’Alessandro, R., Franco, I., & Gallego, Á.J. (eds.), The verbal domain, 255-278. Oxford: OUP.
Wood, J. (2020). Icelandic nominalizations and allosemy. Yale University: ms. https://ling.auf.net/lingbuzz/005004
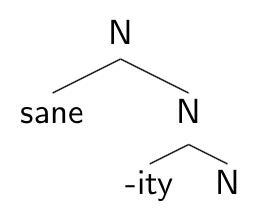
 If sane is really a root, rather than an adjective, then it’s not clear that the top phrase structure of sanity is any different from that of cat, consisting of a root adjoined to a category head.
If sane is really a root, rather than an adjective, then it’s not clear that the top phrase structure of sanity is any different from that of cat, consisting of a root adjoined to a category head.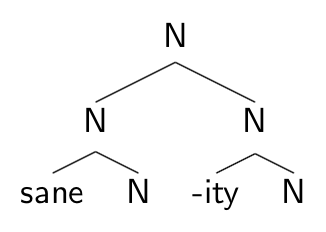
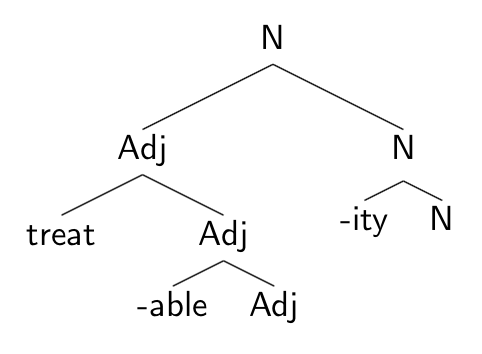
 that do not change category would either not be heads (perhaps they would be “adjuncts”) or would be category-less affixes, with the category of the stem “percolating” up by default to be the category of the derived form.
that do not change category would either not be heads (perhaps they would be “adjuncts”) or would be category-less affixes, with the category of the stem “percolating” up by default to be the category of the derived form.