Recall that a grammar provides a representation of the words and sentences of a language. For standard generative grammars, the grammar is a finite set of rules that describes or enumerates an infinite list (of words and sentences). In a previous post, we conceptualized word and sentence recognition as a process of determining from auditory or orthographic input which memb er of the infinite list of words or sentences we’re hearing or reading. Just as in “cohort” models of auditory word recognition, one could imagine for sentence recognition a cohort of all the sentences compatible with the auditory input at each point in a sentence, and a probability distribution over these sentences. Each subsequent phoneme narrows down the cohort and changes the probability distribution of the remaining candidates in the cohort.
| The cat … |
|
|
|
| /s/ |
/sɪ/ |
/sɪt/ |
/sɪts/ |
| simpers |
simpers |
sits |
sits |
| sits |
sits |
sitter |
|
| sitter |
sitter |
… |
|
| sniffed |
… |
|
|
| … |
|
|
|
From one point of view, syntactic theory provides an account of the nature of the infinity that explains the “creativity” of language – that we understand and produce sentences that we haven’t heard or said before. The working linguist is mostly less concerned with the mathematical nature of the infinity (the subject matter to which the “Chomsky hierarchy” of grammars is related) and more concerned with what the human solution to infinity we describe in Universal Grammar tells us about the nature of language and matters like locality restrictions on long-distance dependencies. In my post on phrase structure rules and extended projections, I emphasized aspects of grammar that are finite. The core of a sentence, for example, could be viewed as the extended projection of a verb, and thus the set of sentences described/generated by the grammar could be a finite paradigm of the possibilities allowed in an extended projection.
But of course, while the set of inflected forms of a verb may be finite (as it is in English, for example), the set of extended projections of a verb are obviously not. While there may be a diverse set of “structure building” possibilities to consider here for multiplying the extended projections of verbs, the two most central considerations for infinity are usually called “arguments” and “adjuncts.” Argument noun phrases, or technically Determiner Phrases (DPs) in most contemporary theories, may occur as subjects and complements (e.g., objects) of extended projections. DPs (in at least most languages, putting aside the status of Everett’s (2005, et seq.) claims about Pirahã) may contain DPs, which may contain DPs, leading to infinity (the story about children in a country with an army with an unusual set of vehicles…). For adjuncts, consider at least the possibility of repeated prepositional phrase modification of verb phrases as a form of infinity (She played the piano on Thursday in Boston on a Steinway with a large audience in 80 degree heat…).
As noted in a previous post, the linguistically interesting account of these types of infinities involve recursion. DPs may occur in various positions, including within other DPs, but the structure of the DP is the same wherever they occur. That is, a DP within a DP has the same structure and follows the same rules as the containing DP.
Now it’s not entirely true that the position of a phrase doesn’t determine any aspects of its internal structure. For example, the number of a noun phrase (e.g., singular or plural), which is related to the number of its head noun, determines whether it may appear as the subject of __ is a good thing (Soup is a good thing, yes; *Beans is a good thing, no). So appearing as the subject of an agreeing verb determines aspects of the internal structure of subjects in English. And the verb phrase put on the table is grammatical in the context of What did you put on the table, but not in the context of *We put on the table. So being in the context of e.g., a wh-question determines aspects of the internal syntax of the VP.
Chomsky’s (1995) Minimalist Program offers one theory of the limits on this contextual determination of the internal structure of phrases. In this theory, a set of important constituents, such as DPs and verb phrases (the part of the extended projection of a verb that includes the subject DP), are “phases.”
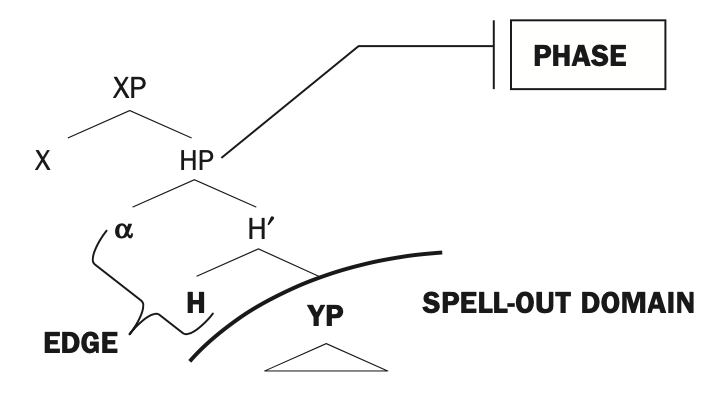
Phase diagram (Citko 2014: 32)
A phase presents to the outside world only its “label” and constituents at its “edge” (at the top of the phase, α above). The label of a phase is a finite set of features, including those like number which would be relevant for subject-verb agreement. The edge of the phase would include what in what (you) put on the table, which is associated with the object position between put and on the table. So the verb phrase put on the table is only grammatical when the object of put appears at the edge of the verb phrase, and the appearance of the object at the edge will insure that the verb phrase is embedded within a larger structure that allows the object to appear in an appropriate position (What did you put on the table?).
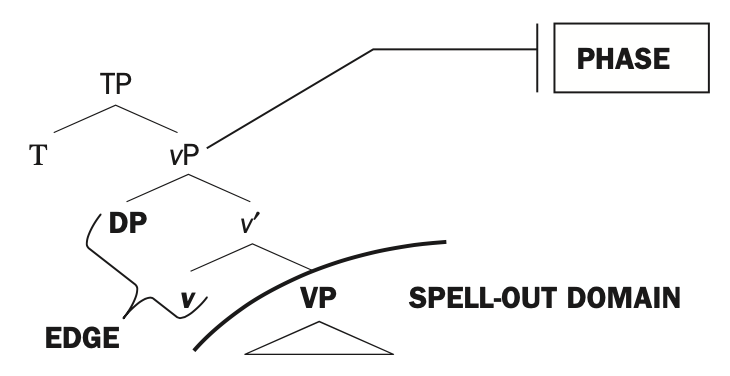
Phase diagram for verb phrase (Citko 2014: 32)
The Minimalist Program allows for some information from inside a phase to matter for the grammatical embedding of a phase in a larger structure, but it does not allow the larger structure to mess with the internal structure of the phase beyond “selecting” for features of the label and features of the edge. And phases within phases can only help determine the grammatical position of the containing phase if they contribute features to its label or constituents to its edge.
Adopting the phase approach as a means to constrain infinity yields grammars that are not problematic to use in “parsing” (assigning a grammatical structure to) sentences as we hear them phoneme by phoneme or word by word (see e.g., Stabler (2013) and Fong (2014) for examples of “Minimalist” parsers). However, even phase-based infinity causes important difficulties for assigning a probability distribution over the members of a candidate set of sentences to compare to the linguistic input one hears or sees. How much probability should we assign to each of the infinite number of possible DPs as the subject of a sentence, for example, where the infinity is generated by DPs within DPs?
Even without these issues with infinity, the locality of syntactic dependencies, as captured by phase theory, itself puts pressure on any simple cohort style theory of sentence (or word) recognition. Since no information within a phase apart from its label and the constituents at its edge can interact with the syntactic structure above the phase, it’s not clear whether shifting probabilities for the internal structure of the phase should affect the probabilities for the containing structure as well. That is, once one has established the label and edge features of a subject DP, for example, the probability distribution over the cohort of compatible extended projections of the verb for which the DP is subject may be fixed, independent of further elaborations of the subject DP, including possible PP continuations as in the story about children in a country with an army with an unusual set of vehicles… – as far as the extended projection of the verb is concerned, we may be done computing a probability distribution after the story about children. Given the way phases fit together, this consideration about how the internal structure of a phase may affect processing of a containing phase covers one issue with infinity as well.
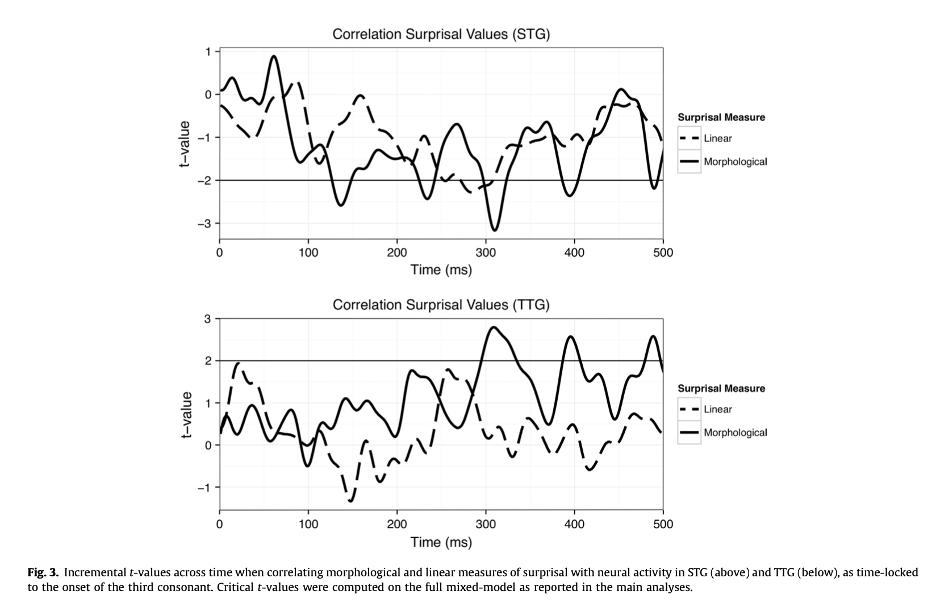
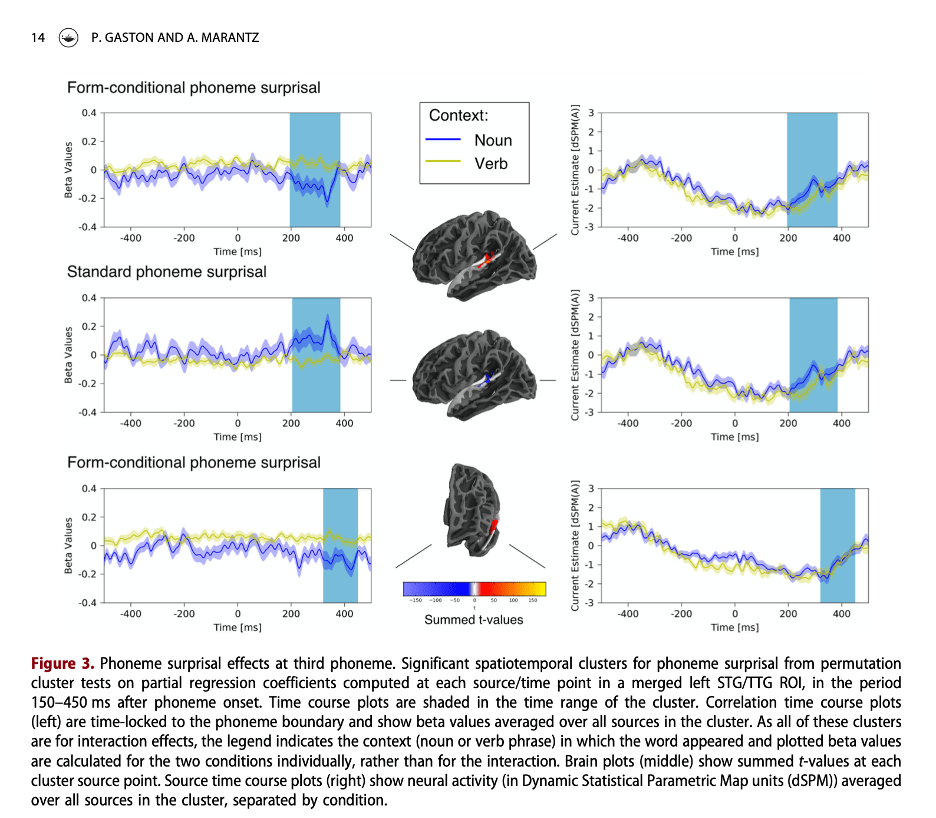
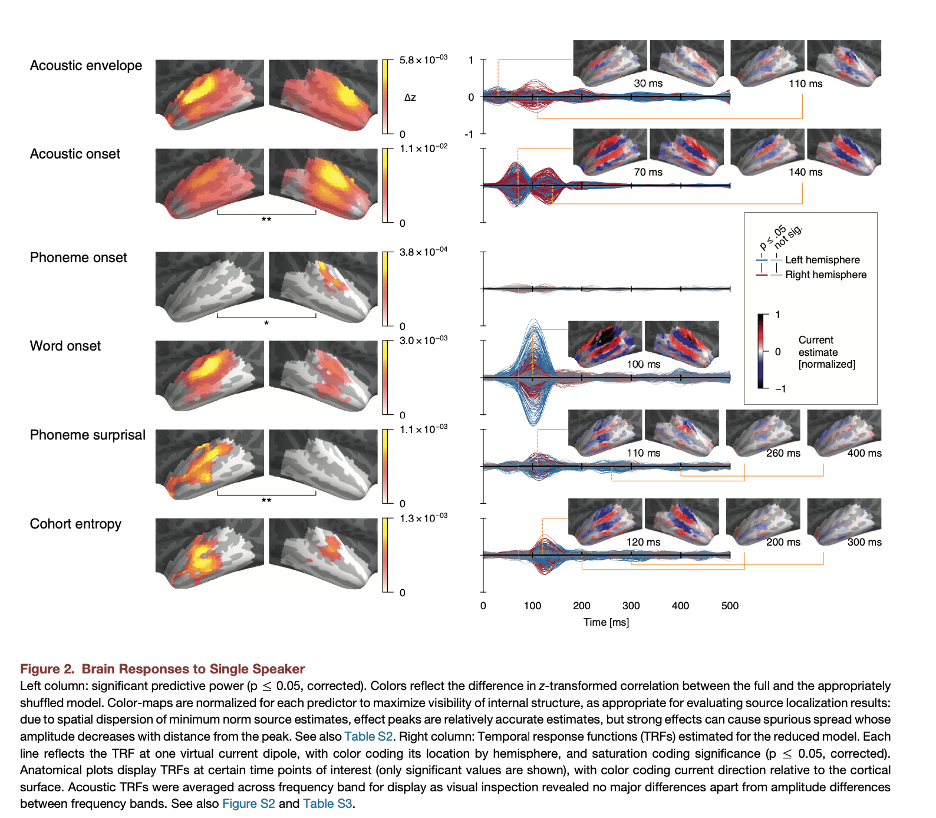
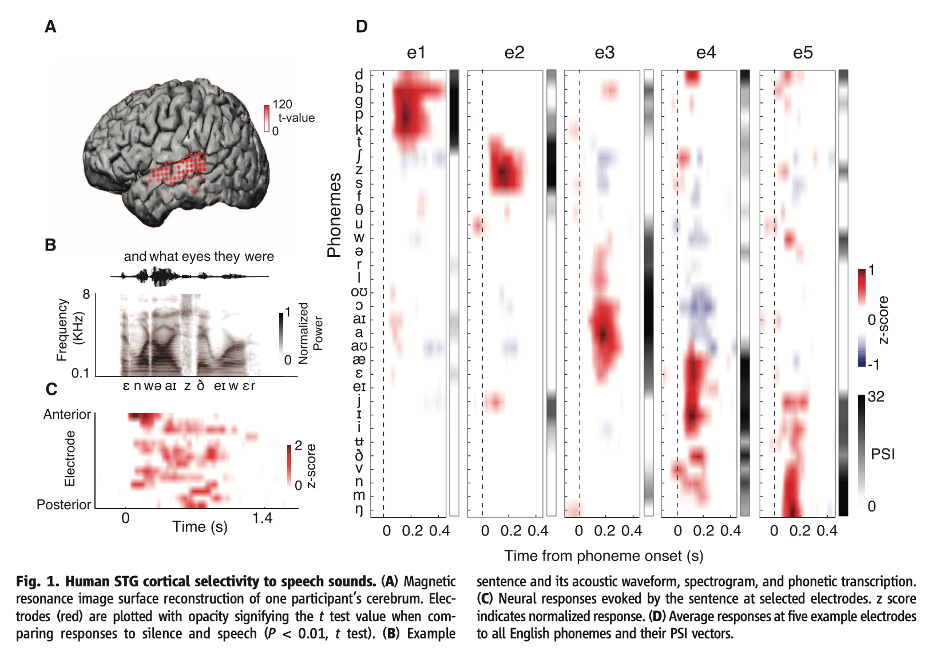
Note that cohort-style analyses of information-theoretic variables like phoneme surprisal always assume that the computation of cohorts can be reasonably accomplished while ignoring some possible context effects. The cohort is a set of units, perhaps morphemes or words. In any situation of language processing, there are an infinite set of contexts to consider that might affect the probability distribution over the members of the cohort, including larger words, phrases, sentences, and discourse contexts. Any experimental investigation of phoneme surprisal based on probability distributions over units must assume that these computations of cohorts and probability are meaningful even without computing the influence of some or all of these possible contextual influences.
Our MorphLab has some data, and an experiment in progress, that are relevant to this discussion. In Fruchter et al. (2015), subjects were visually presented with two-word modifier-noun phrases, one word at a time. For phrases where the second word is highly predicted by the first, like stainless steel, we found evidence that subjects retrieve the representation of the second word before they see it. This response was modulated by the strength of the prediction, but also, surprisingly, by the unigram frequency of the word. That is, even when a word is being retrieved solely on the basis of prediction, the relative frequency of that word compared to other words in the language, independent of context, modulates processing. This suggests the possibility that cohort-related phoneme surprisal responses might be driven at least in part by probability distributions over morphemes that are context-independent. Partly to test this possibility, Samantha Wray in the NeLLab is analyzing data from an experiment in which Tagalog speakers listened to a variety of Tagalog words, including compounds and reduplicated forms (involving full reduplication of bisyllabic stems). If frequency-based, but context-free, cohorts of morphemes are always relevant for phoneme surprisal, then phoneme surprisal phoneme by phoneme in the first and second copies in a reduplicated stem should be similar. By contrast, if one considers the prediction of the second copy in the reduplicated form from the first, the contextual phoneme surprisal in the second part of the reduplicated word should look nothing like the phoneme surprisal for the same phonemes in the first part of the word. So far, context-free phoneme surprisal in the second copy seems to be winning, although there are numerous complications.
Returning to the sentence level, the phase may provide a relevant context-free “cohort” domain for assigning probability distributions to an infinite set of syntactic structures. Without abandoning the idea that syntactic processing involves consideration of whole sentence syntactic structures, we can reduce our cohorts of potential structures to finite sets if we shield phase-internal processing from the processing of the larger structures containing the phase. When we’re processing a structure containing an embedded phase, we consider only the finite set of possibilities for the label and edge properties of this phase. Once we’re processing inside the phase, we define our cohort of possible structures using only external contextual information that fix the probability distribution over the phase’s label and its edge properties.
Applying this approach to morphological processing within words involves identifying what the relevant phases might be. Even within a phase, we need to consider the various ways in which a contextually-determined probability distribution over small (say, morpheme-sized) units might be affected by context. Much more on these topics in upcoming posts.
References
Citko, B. (2014). Phase theory: An introduction. Cambridge: CUP.
Chomsky, N. (1995). The Minimalist Program. Cambridge, MA: MIT Press.
Everett, D. L. (2005). Cultural constraints on grammar and cognition in Pirahã: Another look at the design features of human language. Current anthropology, 46(4), 621-646.
Fong, S. (2014). Unification and efficient computation in the Minimalist Program. In Lowenthal, F., & Lefebre, L. (eds.), Language and recursion, 129-138. New York: Springer.
Fruchter, J., Linzen, T., Westerlund, M., & Marantz, A. (2015). Lexical preactivation in basic linguistic phrases. Journal of cognitive neuroscience, 27(10), 1912-1935.
Stabler, E. P. (2013). Two models of minimalist, incremental syntactic analysis. Topics in cognitive science, 5(3), 611-633.