Background and inspiration:
When I did my case study of image-to-image translation, I found a very interesting project, which is called “person-to-person video transfer. The designer Dorsey first records the speech of Kerzweil, and then records himself mimic Kerzweil’s pose frame by frame, then he use these two videos to train a model to transfer himself to Kerzweil with the same pose. This project attracts me because it reminds me of the idea of my tiny project of PoseNet. In that project, I use the output of that model to portray a puppet controlled by the strings, so you can control the pose of the “puppet” by your body. And in this final project, I want to improve that project with a more creative conception.
Conception:
Basically, what I want to do is a pose control model, I use DensePose as an intermediate model to generate the pose image of the user, and I will train my own CycleGAN model to generate a human-like image of based on that pose image. So the model can generate human-like images based on the pose of the person in the input, the input can be an image, a video, or camera captured pictures.
Progress:
The model I use is called CycleGAN, and the file I use is the Google Colab version which is provided on this GitHub website. Also, Aven helps me a lot to modify the original code to make it much more convenient to use.
In the training process, I need two data sets, one is the images of people and the other one is the images of pose generated by DensePose. And the model will be trained to build 2 models to generate from one category to another category. And the one I need is the pose to people one.
In the first stage, the people images I used are random. Since my assumption is that if a use images from a lot of people to train the model, the model can generate human-like images with random styles.
So I collect the photo of single person’s full body images from the internet. Also, I found some solo dance videos, and then collect frames in those videos. Since all the dataset images for CycleGAN must be squared, so I wrote a very simple Processing program to help me resize the photo without changing the ratio, and it will add white padding to the empty part.
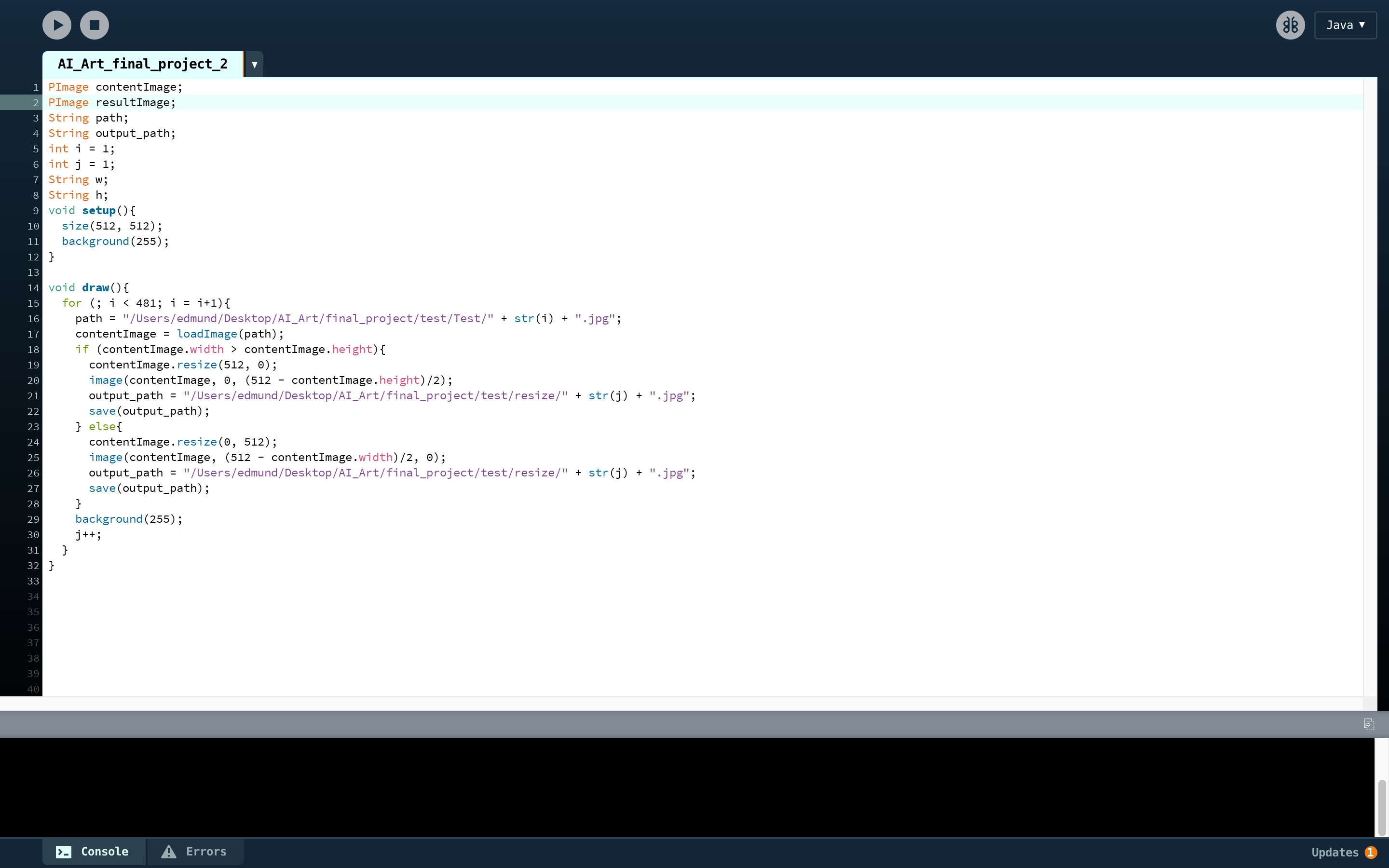
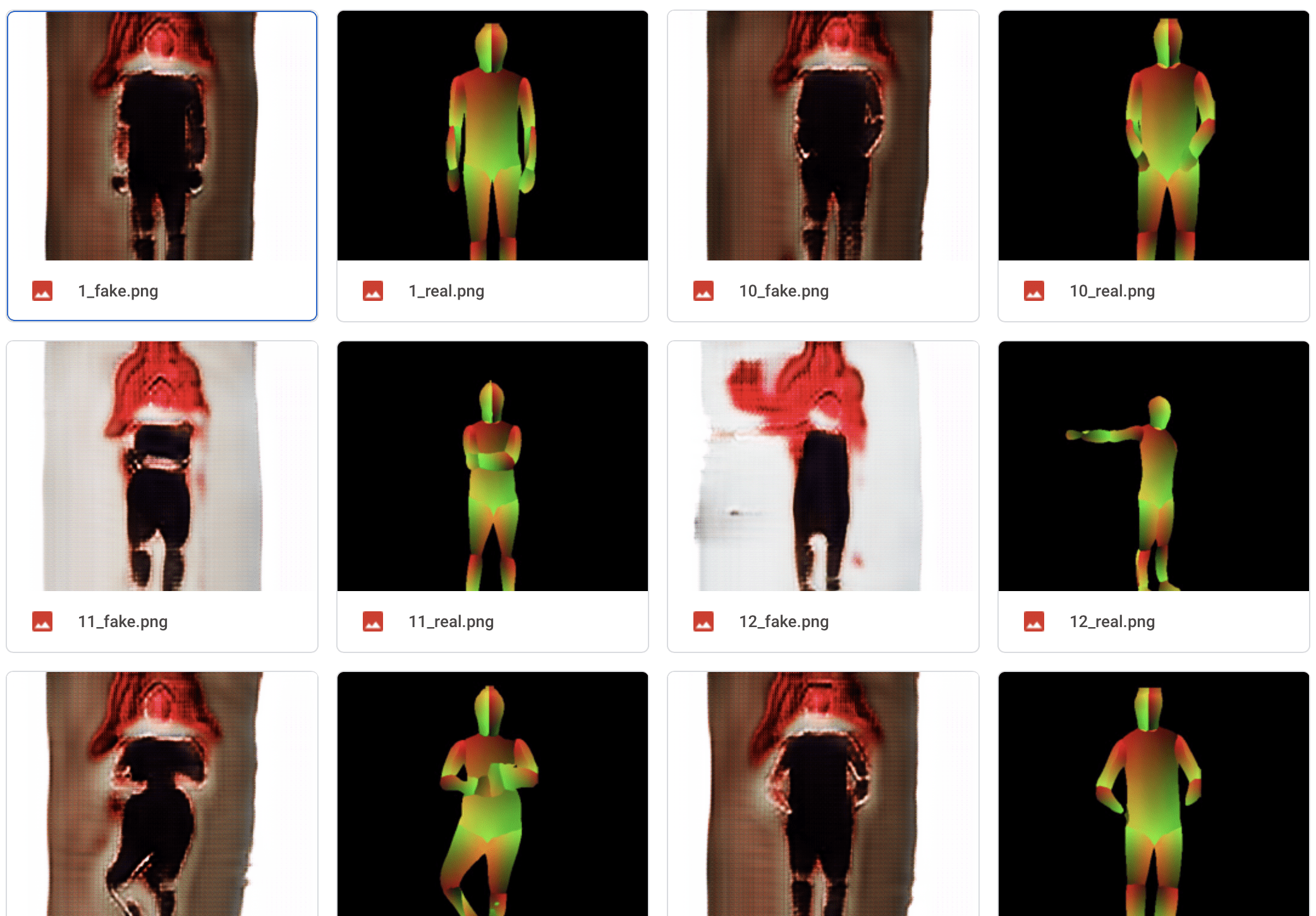
After I got all these resized people images, I send them to RunwayML DensePose model to generate the pose images.
After getting all the images I need, I start to train the model on Google Colab. I have trained 8 models and about 1000 epochs in total.During this process, I have changed my dataset for many times, including deleting some images of which I think it is not good for training and adding new images to it. But I found the results are not much similar to what I would expect. Firstly, the characters and details of a human is not shown clearly in the images it generates. And most importantly, one model cannot generate images of different color styles and each model has its own color style. Though I can still make the images random by using many models. But that kind of random structure —— “random choice in the styles I choose” is different of what I want to achieve —— “random generating elements based on what machine has learnt from the learning process”.
(below are testing results of models belonging to different epochs in the same training process)
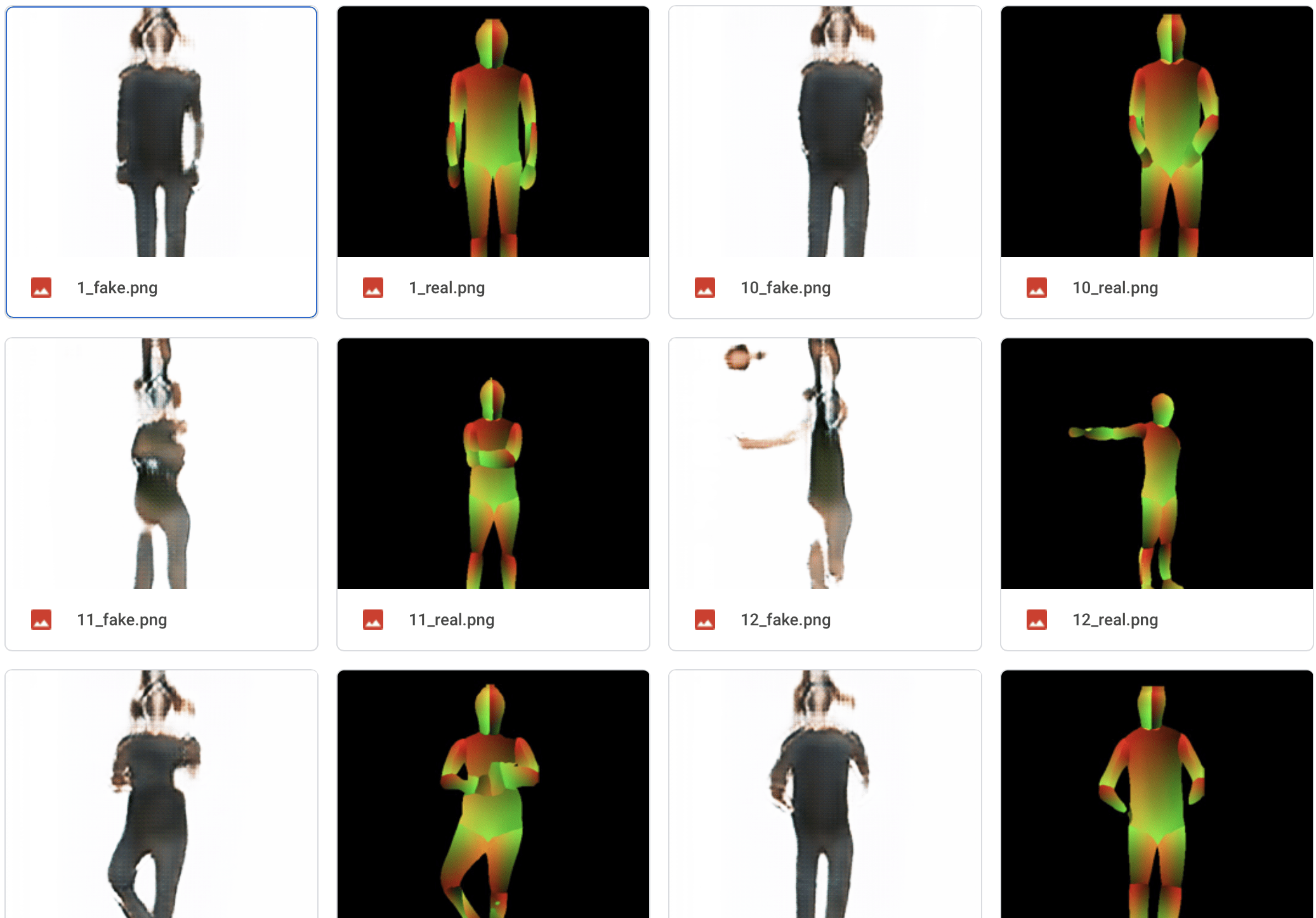

So I give up the original plan and step into the second stage. I need to use the images of a certain person, and both Aven and I think choosing the images of myself to train the model is a good idea. In this case, the model will be trained to generate Edmund(me)-like images based on the pose of the person in the input. So I take some videos of myself and then use the frames as the new training dataset.
This time, I also trained 8 different models but only with 600 epochs. I notice that it is really quick for the model to achieve its best performance (about 20th-40th epochs) and after that the images it generate will get really abstract. But after about another 100 epochs, the performance of the models will return to the standard of those models generated from 20th-40th epochs. So, generally, I only need to train about 50 epochs for each model. And the quality of the images it generates are much higher than the first stage, the human features are easier to detect.
Below is the testing result of a well-performed model.
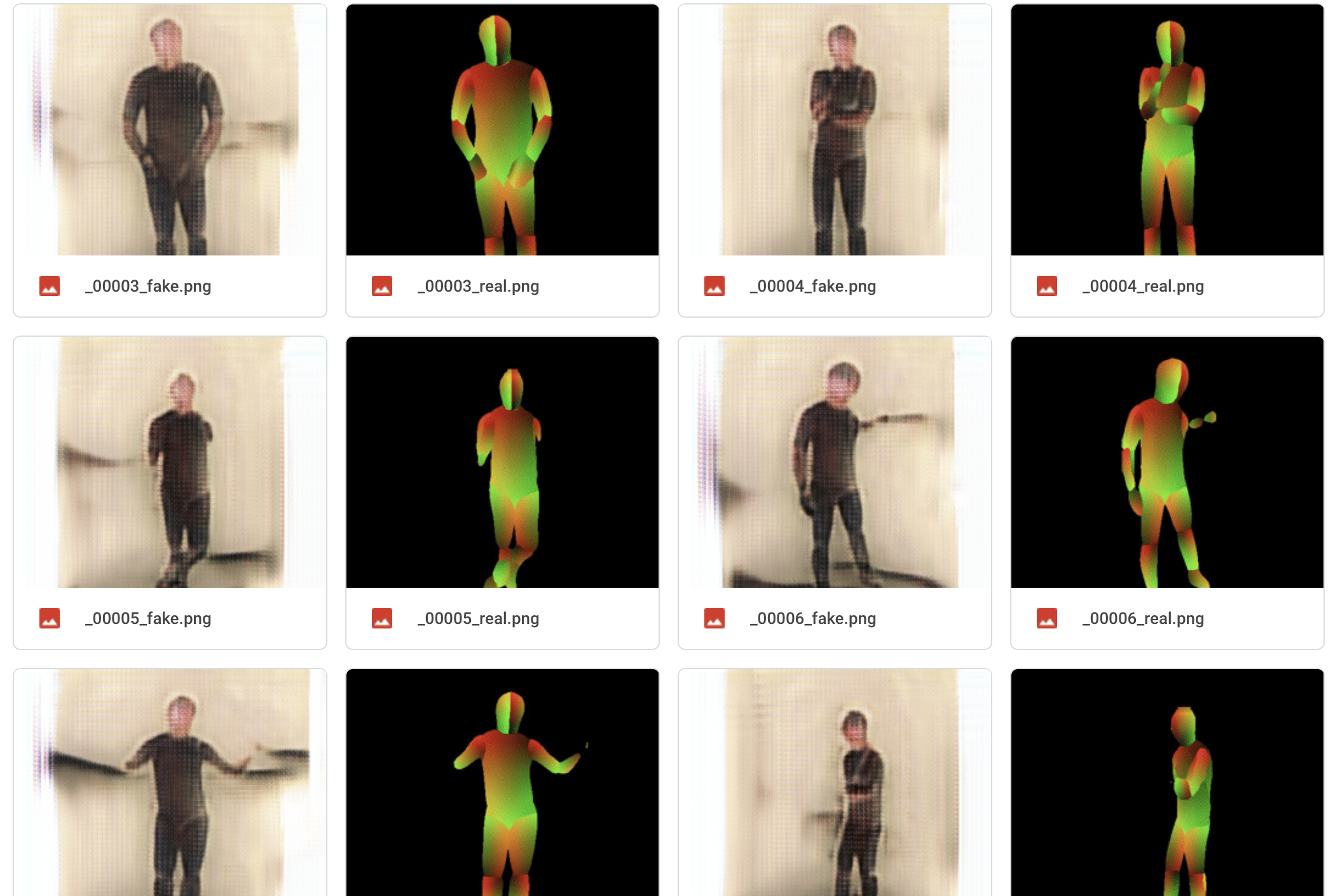
The result is really good among all the models, you can tell the black hair on my head, and you can see half of my arm is not wrapped up by the shirt, which is portrayed with a warmer color. And if you see more carefully, you can see my shirt is in dark green and my jeans is blue. But the shapes of “me” in the generated images are too regular, by too regular, I mean it is not creative and it is strictly same to the pose images.
And my final choice is here. I like it because its style is kind of abstract. The shape of “me” is not 100% the shape of a human, but it may curve or round in a certain way. I like this kind of abstract style to recreate myself. In the meanwhile, the features of me can still be seen clearly.

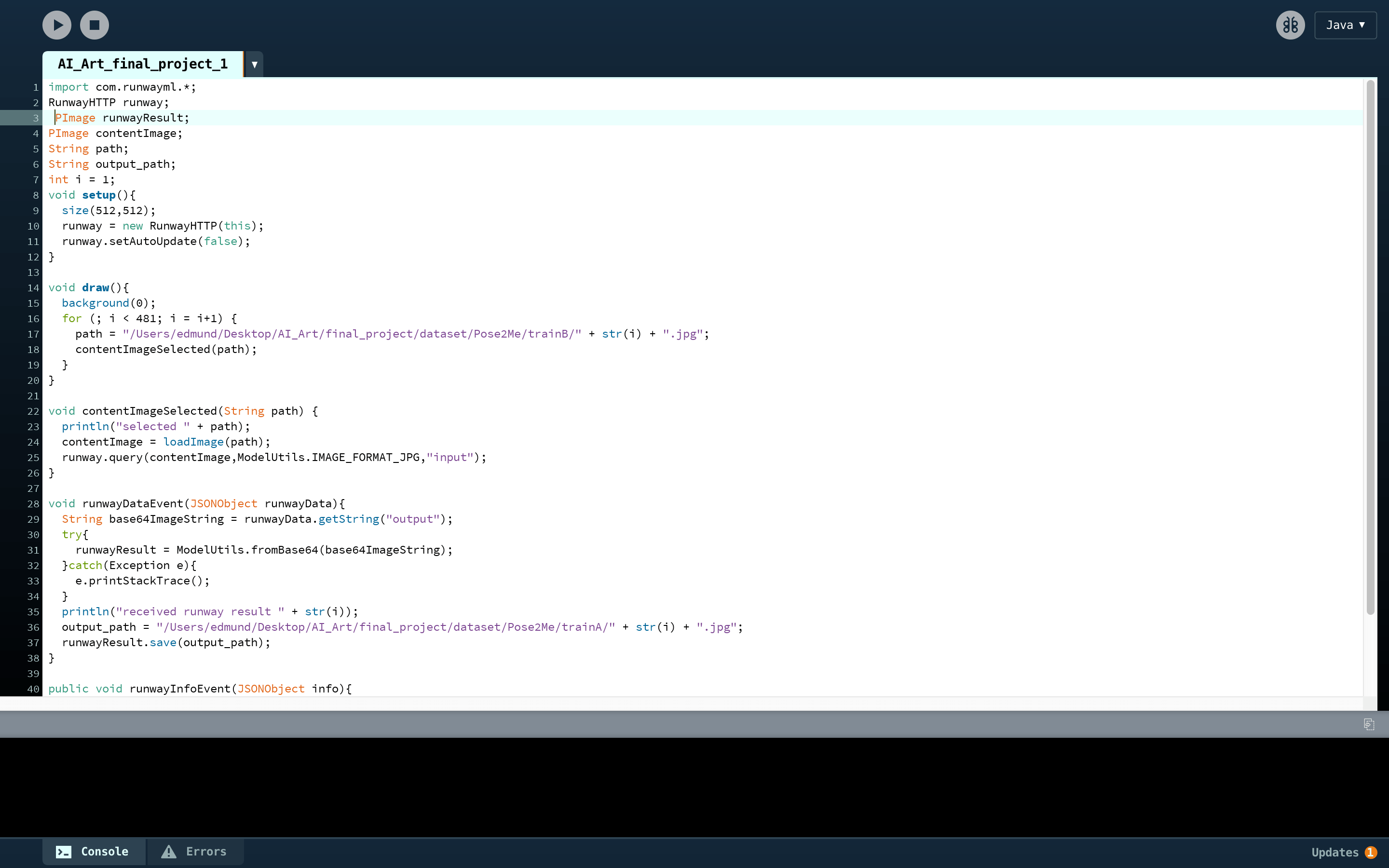
After I get that model, I run it locally and then make RunwayML connect with that local server, then I wrap this model up with the DensePose model, so it now can get the images of a person, and the generate the images of myself, and the user can control my pose with their own bodies.
Here is the screenshot of the workspace, and you can use processing to send data to and get data from this model with a code very similar to the first one shown before.
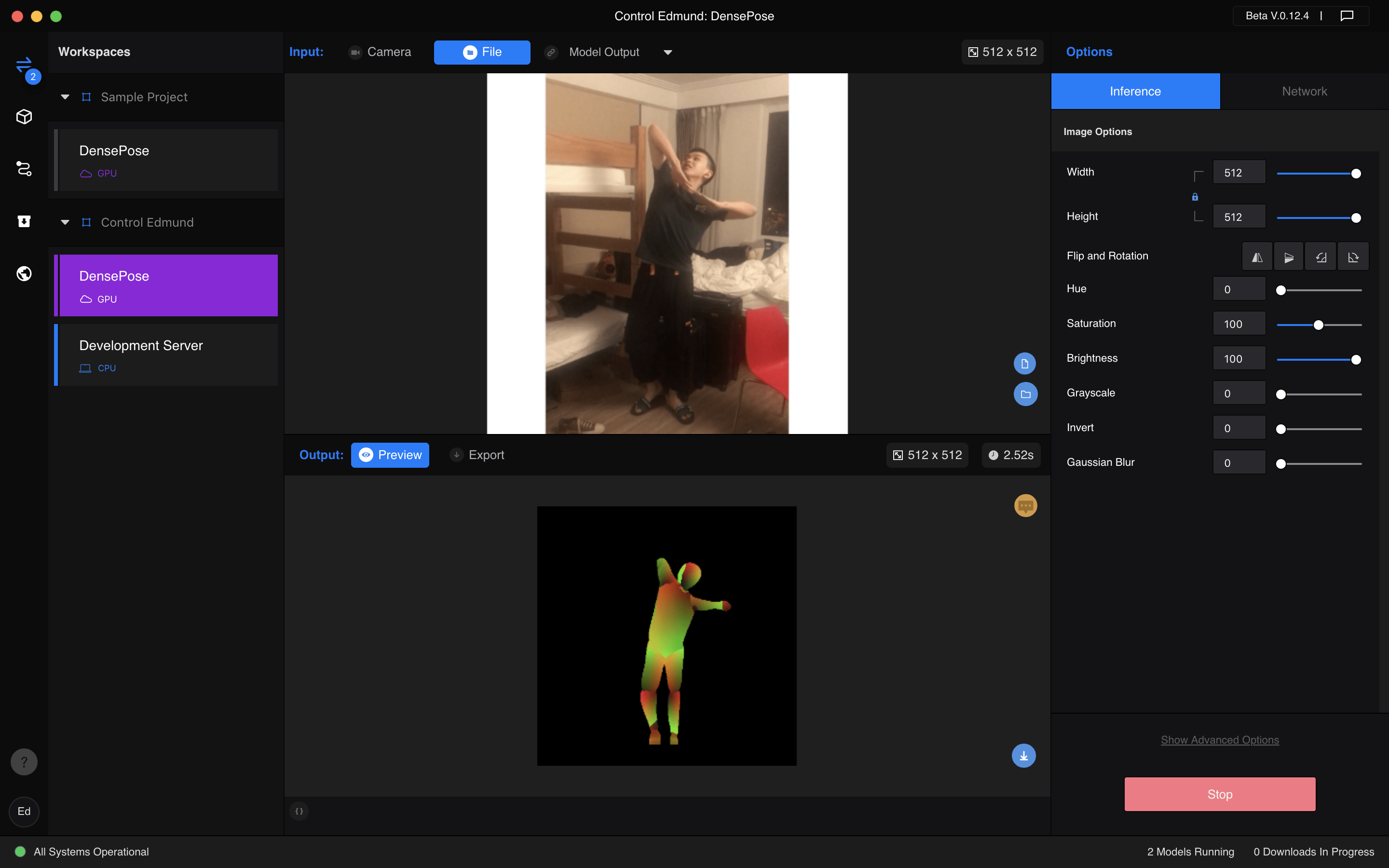
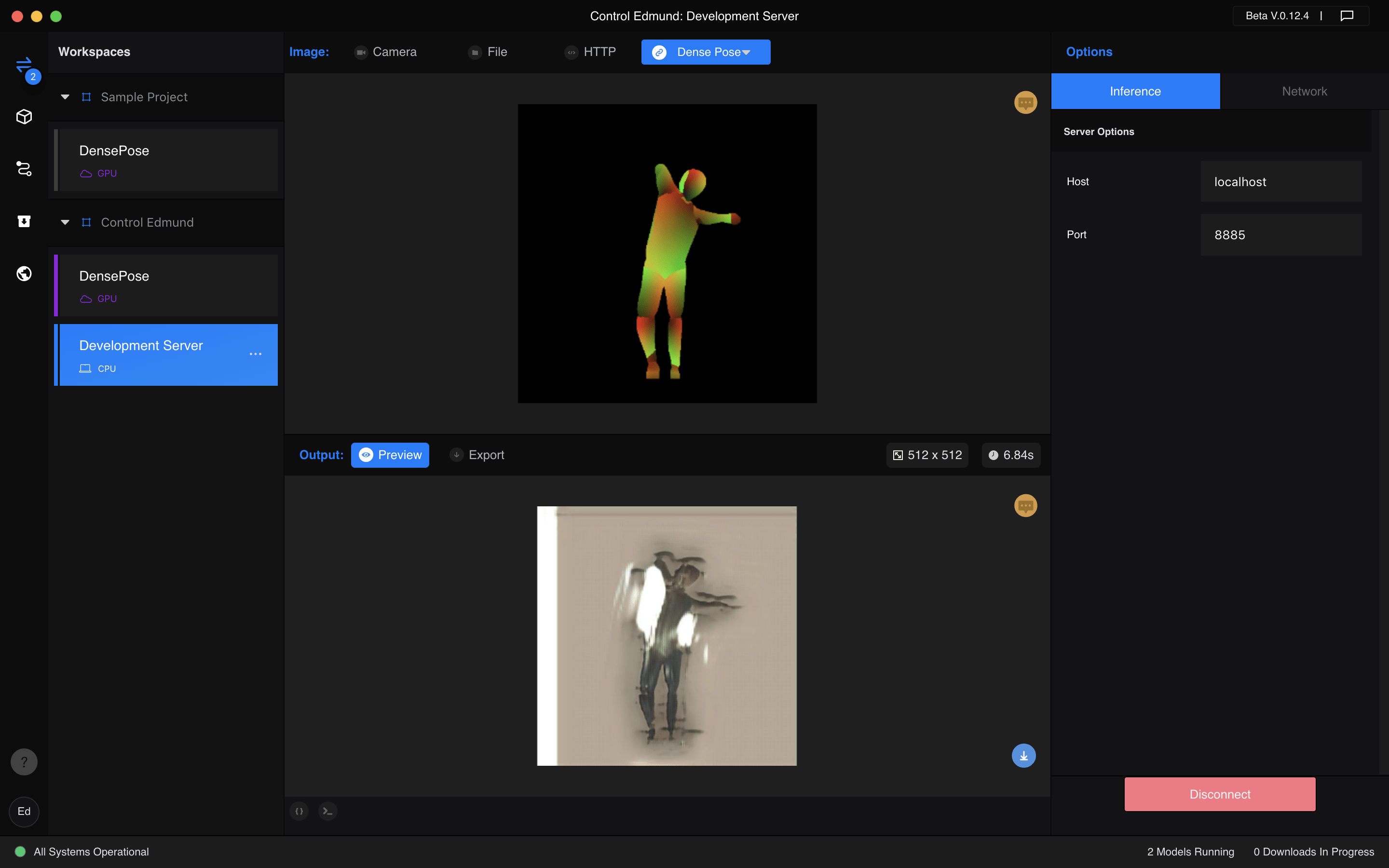
Unfortunately, the performance of the model in RunwayML is much worse than its performance during the testing process in Google Colab, the results should be the same but there seems to be something wrong. I have tried many ways but still cannot find how to solve it.
Also, since I can only use it locally with a CPU, the runtime of this model is really long. So it does not support a live camera as its input (actually the live camera is the most interesting part, what a pity).
Here are the images of my friend and the images generated by the model (in Google Colab) based on those images.

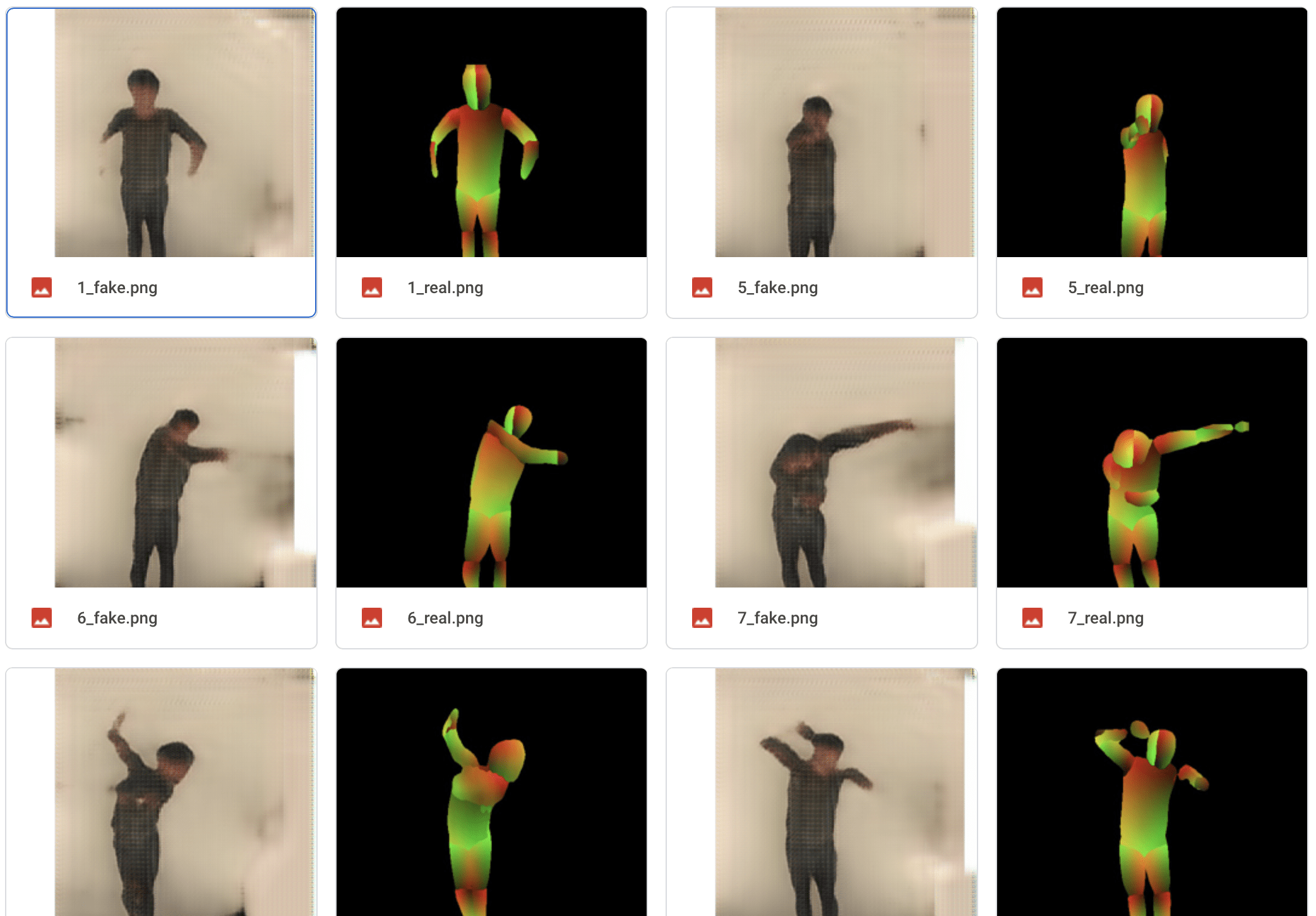
Future Improvement:
Firstly, of course, I need to fix the problem with RunwayML, or find another convenient way to run my model.
Secondly, I want to upload this model to a online server then I can use GPU online to help me compute the result, then the model can process with live camera videos.
Thirdly, maybe I can train it with images of more than one person’s poses, then the model may learns to change anyone in the image to me. It’s cool to imagine the world is filled with myself.