After the installation, I first tried with some models I am interested in and run them remotely. But it turns out to take about 5-10 minutes while the inference time it reports is only about 10 seconds. So I downloaded them and run them locally and this makes them much faster.
The first model I tried is called Deep-Portrait-Image-Relighting. It is a very useful one. It can helps to modify a photo by relighting it. For example, you can change the light to left, right, bottom, top, top right, bottom left and so on. When you are not satisfactory with the light effect of your photo, I think this will help a lot.
The original image:

Right:

Bottom:

Top-right:

Bottom-left:

The second model I tried is called CarttonGan. This model learn from the painting of 4 famous Japanese cartoonist —— Hosoda Mamoru, Hayao Miyazaki, Kon Satoshi’s Paprika and Shinkai Makoto. And this model can modify the original image by changing its art style similar to those cartoonists paintings.
The original image:
Hosoda:

Hayao:

Paprika:

Shinkai:

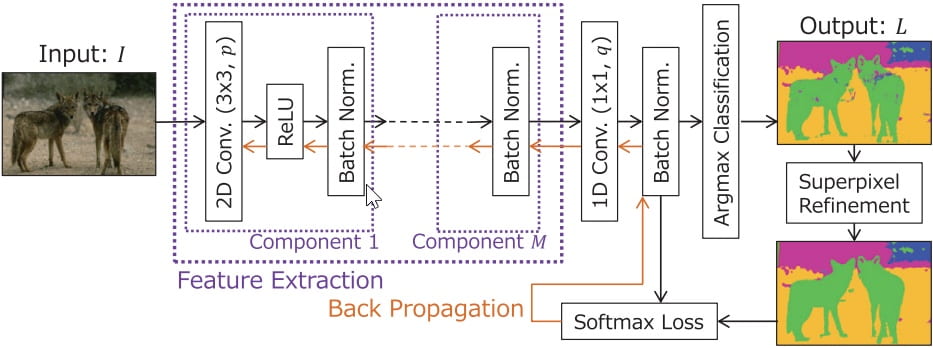
The last model I tried is called Unsupervised-Segmentation. Basically, it tries to detect the pixels belonging to the same block (cluster) and then change them to the same colors. I have done some coding of this model last semester in ICS course.
The original image:

After segmentation:

I have done some further research on this model.The basic structure of this model is to iterate and give the same table to similar pixels and then give the same color to the pixels in the same table.
Iterate it for T times (we can change T)
Use CNN to get the feature of the image
According to the feature we get, for each pixel, find its cluster
For every cluster of this image
Find the most type (color) in this cluster
For every pixel in this cluster, assign the type (color) to it
Here is a whole picture of this model
And this is a YouTube video introducing another model of segmentation.