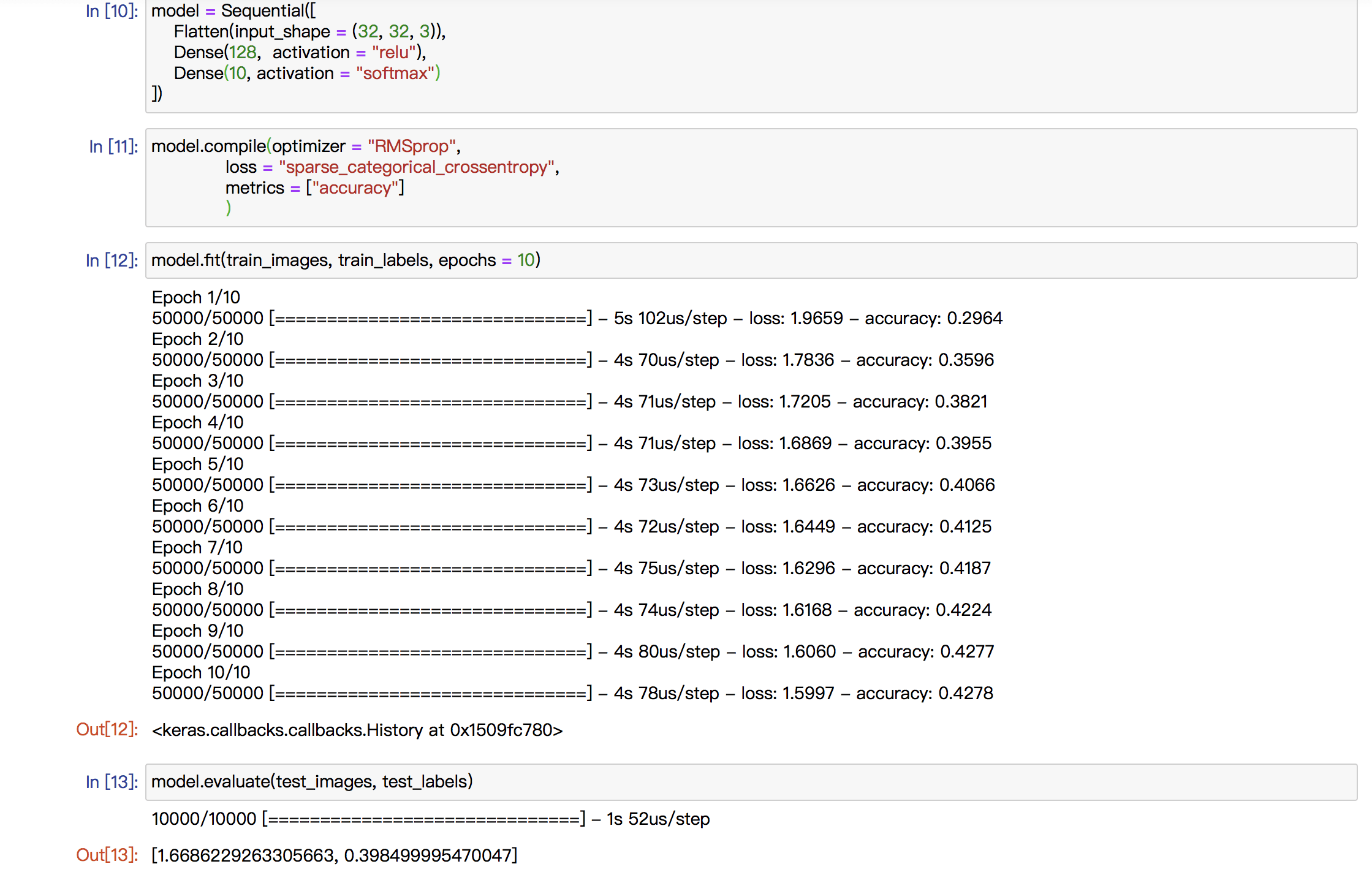
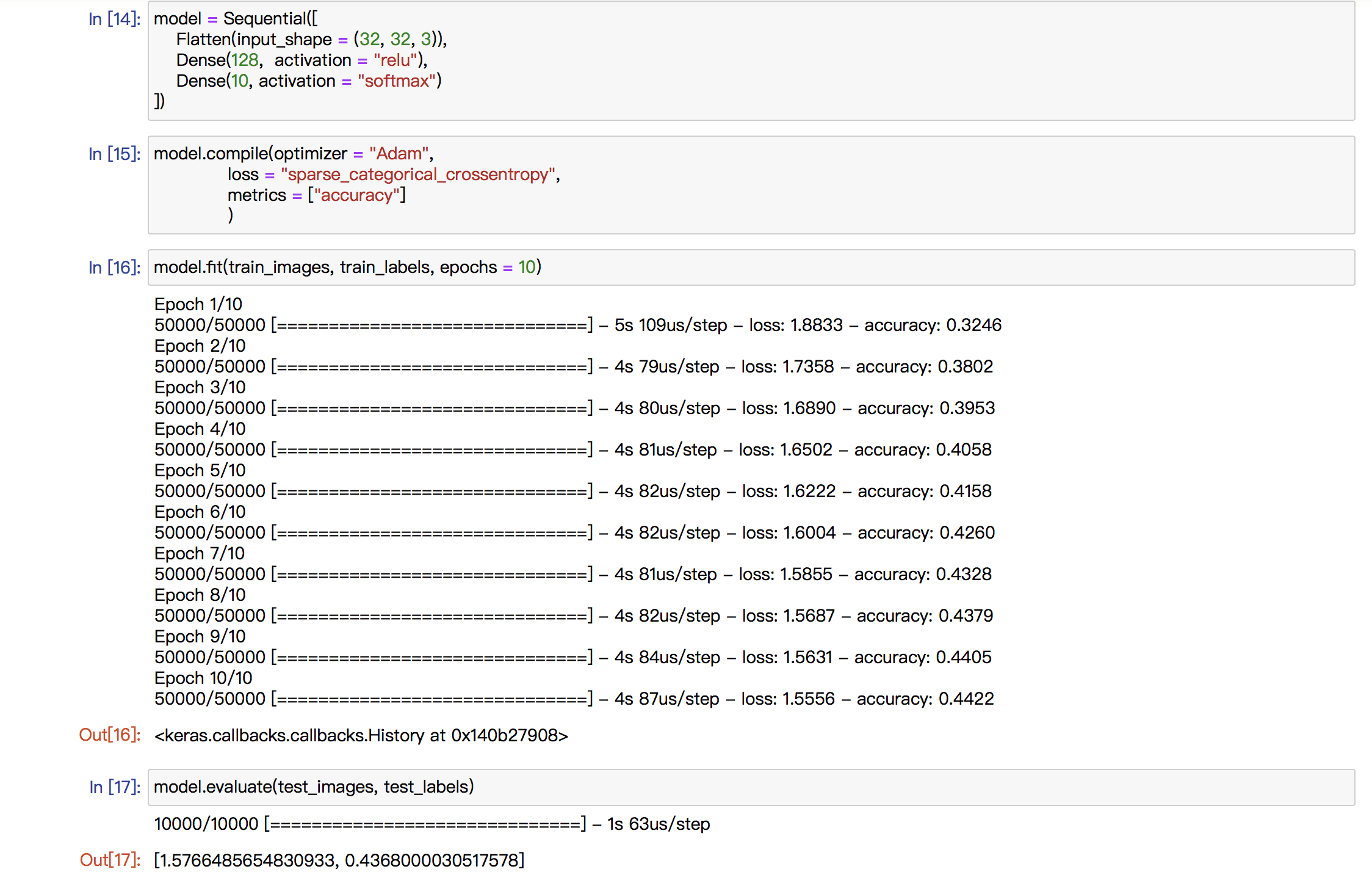
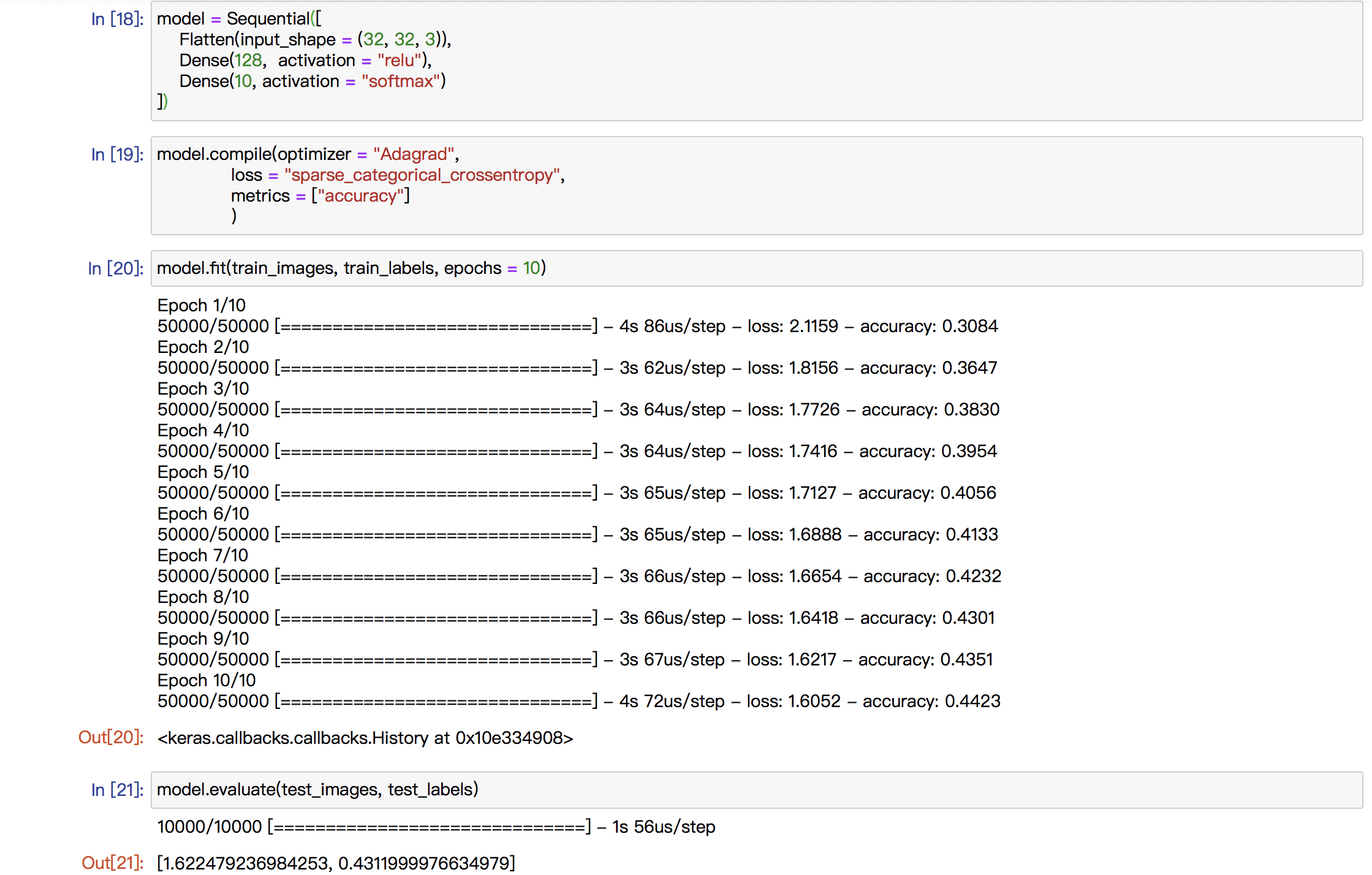
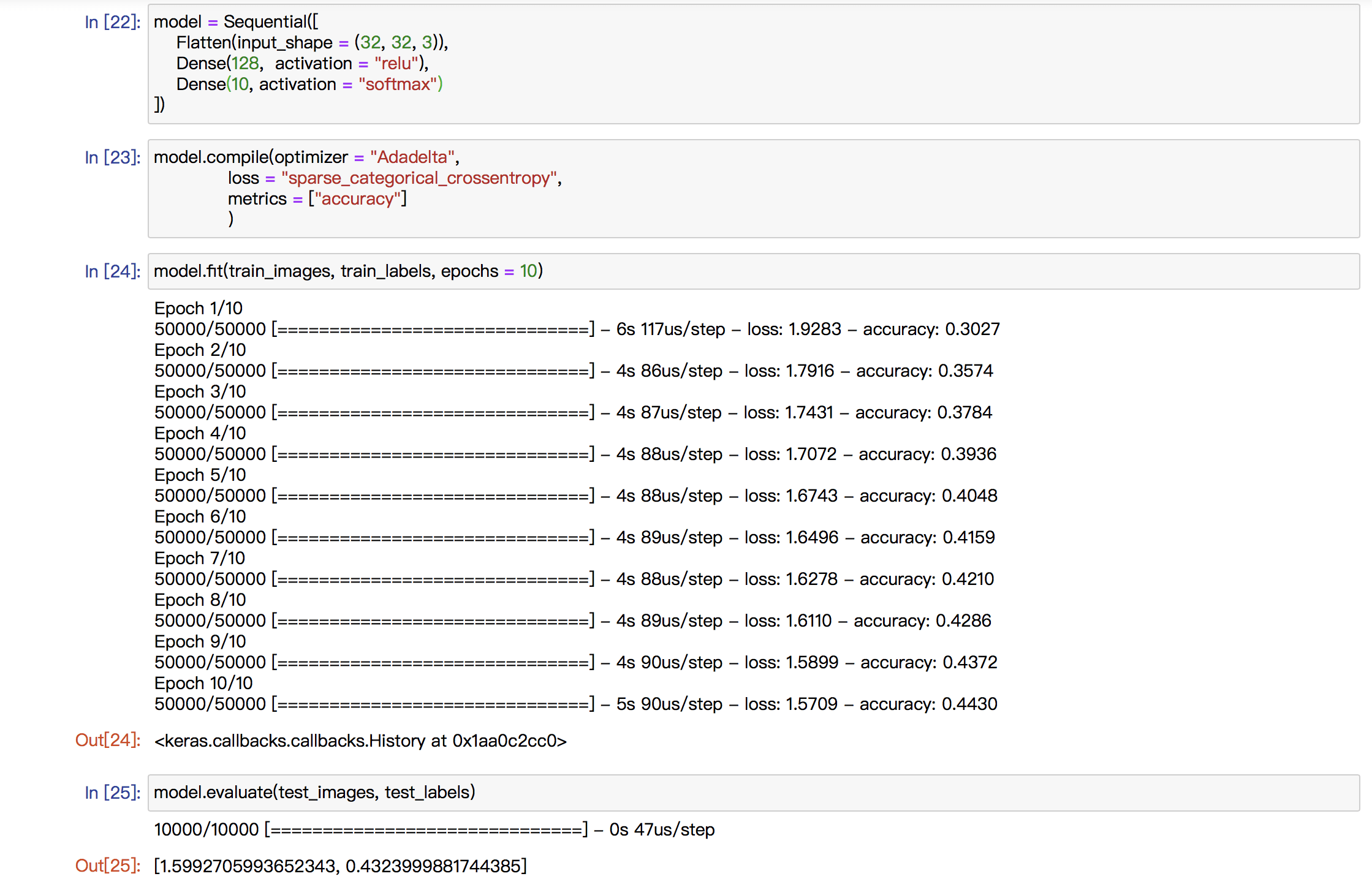
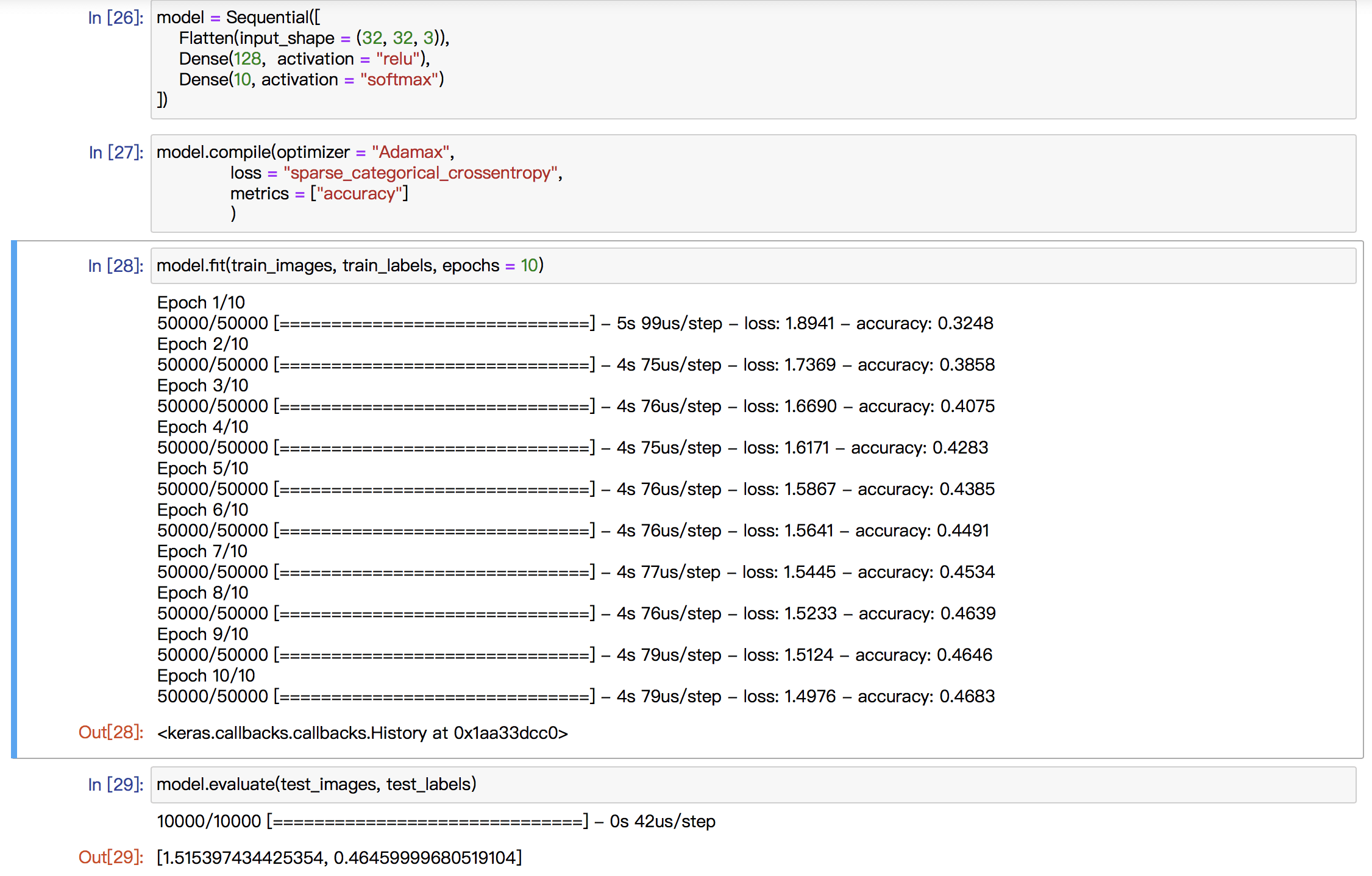
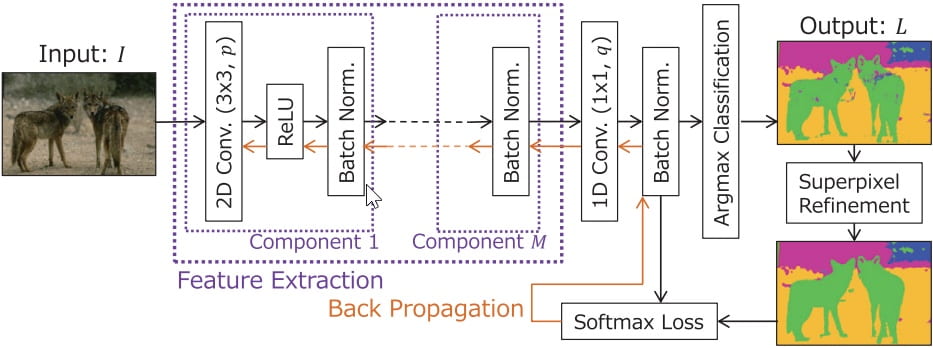
Basically, my midterm project is going to be a visual one and I will explore with the object detection technique. Currently, I want to use “Yolo V3” but it is not decided yet. What I want to do is to portray the world in a machine’s view.
Since the object detection model just tries to discover the objects it can recognize and provide its label, position and position. It does not care the details in those boxes and if there is any difference between the objects belonging to the same label. So, in my mind, the world in machine’s view may be a world filled with repetitive rectangles with different colors. And I want to demonstrate that kind of view in the “Processing” with the help of “runwayML”.


The first image is one of the famous example images of “Yolo V3” and the second one is a simulation of the visual effect of my project. I will cut off the words of the labels and make it a complete visual one. And I may also change the opacity of the boxes based on the possibility of its speculation.
This idea is inspired by some pictures only with simple shapes, I love that simple style with and want to relate it to the machine vision.


And the combination of the simple shapes reminds me of the oil paintings portraying the static objects. When the artists want to evaluate the painting, they will find the borders of the each object in the painting in their mind, just like the object detection model does to the input images. The artists do this to observe if the objects in the painting achieve a beauty of balance between the objects. And my object may also helps to discover the beauty behind the realistic images.