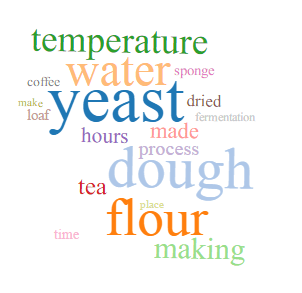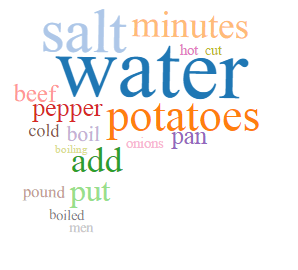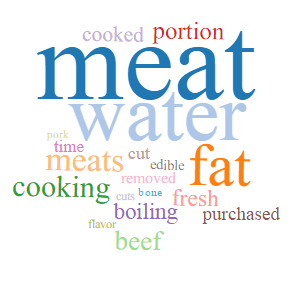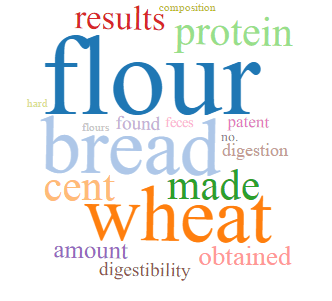Topic modeling is a useful way to look for trends and patterns in the collection which may add to our understanding of early cookbooks. What is topic modeling?
As Megan R. Brett explains in Topic Modeling: A Basic Introduction, topic modeling is a form of text mining, a way of identifying patterns in a corpus. You take your corpus and run it through a tool which groups words across the corpus into ‘topics’ (Brett, 2012). Miriam Posner has described topic modeling as “a method for finding and tracing clusters of words (called “topics” in shorthand) in large bodies of texts” (Posner 2012).
Topic modeling is an automated text mining technique that offers a “suite of algorithms to discover hidden thematic structure in large collections of texts” (Blei 2013, 7). Topic modeling is a methodology developed in computer science, machine learning, and natural language processing that has recently become very popular in the digital humanities (Meeks 2013). New digital tools such as MALLET (McCallum 2002) generate comprehensive lists of subjects through statistical analysis of word occurrences in a corpus. The content of the documents, not a human indexer, determines the topics (Jockers 2013, 124). Unlike traditional classification systems with a pre-existing taxonomy of terms, topic modeling creates topics by clustering words that frequently occur together in a text. The resulting topical clusters can be readily interpreted as subject facets by human readers, allowing them to browse the topics of a collection quickly and find relevant material using topically expanded keyword searches (Mimno and McCallum 2007).
The topic models for Early American Cookbooks were generating using the Meandre Topic Modeling algorithm created by Loretta Auvil and available via the HathiTrust Research Center Portal. The algorithm serves to “identify “topics” in a workset based on words that have a high probability of occurring close together in the text. Topics are models trained on co-occurring text using Latent Dirichlet Allocation (LDA), where each topic is treated as a generative model and volumes are assigned a probability of how likely each topic is to have generated that text. The most likely words for a topic are displayed as a word cloud.” Please see Topics Models for Early American Cookbooks and Topic Models for Government Publications for the word cloud results and the About page for more details on the workflow.
WORKS CITED
Blei, David M. 2013. “Topic Modeling and Digital Humanities.” Journal of Digital Humanities.
Brett, Megan R. 2012. “Topic Modeling: A Basic Introduction.” Journal of Digital Humanities.
Jockers, Matthew Lee. Macroanalysis Digital Methods and Literary History. Urbana: University of Illinois Press, 2013.
McCallum, Andrew Kachites. 2002. “MALLET: A Machine Learning for Language Toolkit.”
Meeks, Elijah, and Scott Weingart, 2013. “The Digital Humanities Contribution to Topic Modeling.” Journal of Digital Humanities.
Mimno, David, and Andrew McCallum. “Organizing the OCA: Learning Faceted Subjects from a Library of Digital Books.” Proceedings of the 7th ACM/IEEE-CS Joint Conference on Digital Libraries. New York, NY, USA: ACM, 2007. 376–385.
Posner, Miriam. “Very Basic Strategies for Interpreting Results from the Topic Modeling Tool.” Miriam Posner’s Blog. 29 Oct. 2012.